New and Improved Peer-to-Peer Replication
For
data distribution requirements that must have updates in multiple
nodes, peer-to-peer replication is ideal. You must worry about
conflicts, but typically they are rare and very easily handled by a
simple conflict handler. Peer-to-peer replication is transactional
replication based, and can have any number of peers. A separate wizard
is used to set up peer-to-peer replication because of its unique
characteristics. Remember, there are essentially no subscribers, just
publishers. All peers are handled by one or more distributors and are
assigned a unique peer originator ID value to help in transactional
consistency and conflict resolution. If you have been doing replication
since the SQL Server 6.5 days, the peer-to-peer configuration topology
viewer is much like that old user interface. Figure 4 shows the special invocation of peer-to-peer creation from SQL Server Management Studio.
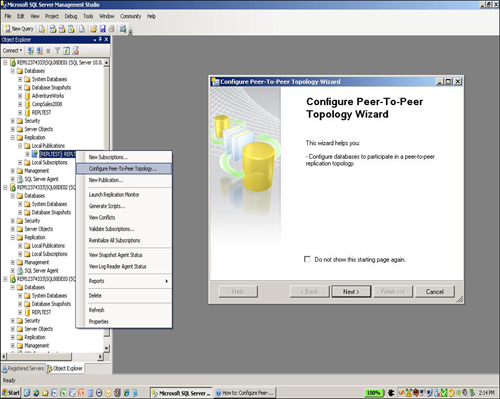
You basically create publications that become shared in the peer-to-peer
topology. You add “nodes” on an equal hierarchical level that
participate in the publication equally. You can add any number of peers
(nodes), and new in SQL Server 2008, this can be done without
interrupting the existing replication topology. Figure 5 shows the setup of a publication for a database named REPLTEST_PEER2PEER and the addition of two nodes to the topology.
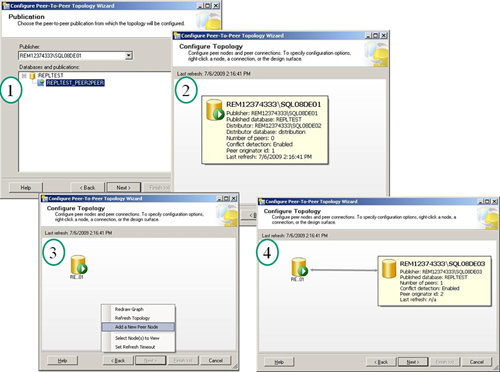
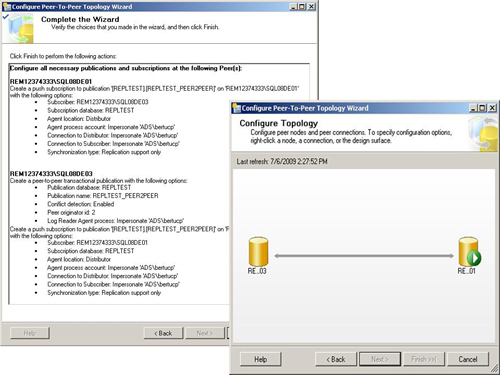
Peers are typically initialized manually for consistency purposes. Figure 6
shows the Configure Peer-to-Peer Topology Wizard summary and the
successful creation of the full (two-node) topology. Note that each node
is assigned a unique originator ID, and conflict detection has been
enabled. Notice also that it really doesn’t matter which node is listed
first in the wizard topology because they are equal (no hierarchy
exists) and the arrow is bidirectional.
The Performance Monitor
You can use Windows
Performance Monitor to monitor the health of your replication scenario.
When you install SQL Server, you get several new objects and counters
in Performance Monitor:
SQLServer:Replication Agents— This object contains counters used to monitor the status of all replication agents, including the total number running.
SQLServer:Replication Dist—
This object contains counters used to monitor the status of the
distribution agents, including the latency and number of transactions
transferred per second.
SQLServer:Replication Logreader—
This object contains counters used to monitor the status of the log
reader agent, including the latency and number of transactions
transferred per second.
SQLServer:Replication Merge— This
object contains counters used to monitor the status of the merge
agents, including the number of transactions and number of conflicts per
second.
SQLServer:Replication Snapshot—
This object contains counters used to monitor the status of the
snapshot agents, including the number of transactions per second.
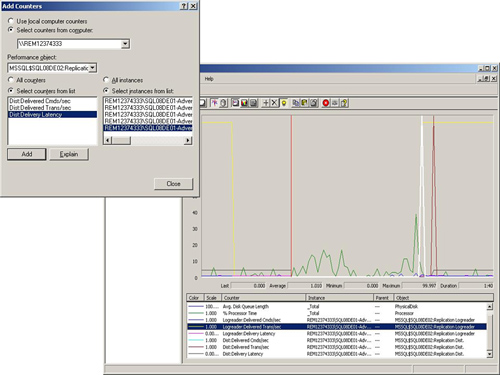
As you can see in Figure 7,
we chose to monitor the typical things critical for replication: the
LogReader counters, the distribution server counters, some default
processor times, and disk queue lengths to keep an eye on load at the
publisher. Figure 19.63
shows some spikes during log reader activity as big transactions hit
the publisher. However, they drop off quickly, easily handling the large
transaction volumes.
Replication in Heterogeneous Environments
SQL Server 2008
allows for transactional and snapshot replication of data into and out
of environments other than SQL Server. This is termed heterogeneous
replication. The easiest way to set up this replication is to use ODBC
or OLE DB and create a push subscription to the subscriber. This is much
easier to make work than you might imagine. SQL Server can publish to
the following database types:
Microsoft Access
Oracle
Sybase
IBM DB2/AS400
IBM DB2/MVS
SQL Server can replicate data to any other type of database, provided that the following are true:
The driver must be ODBC Level 1 compliant.
The driver must be 32-bit, thread safe, and designed for the processor architecture on which the distribution process runs.
The driver must support transactions.
The driver and underlying database must support Data Definition Language (DDL).
The underlying database cannot be read-only.
Backup and Recovery in a Replication Configuration
A replication-oriented
backup strategy will reap major benefits for you after you have
implemented a data replication configuration. You must realize that the
scope of data and what you must back up together have changed. In
addition, you must be aware of the recovery time frame and plan your
backup/recovery strategy accordingly. You might not have multiple hours
available to you to recover an entire replication topology. You now have
databases that are conceptually joined, and you might need to back them
up together in one synchronized backup. Figure 8 shows overall backup strategies for the most common recovery needs.
Figure 8. Common backup strategies for different recovery needs.
| Recovery Need | Backup Strategy |
|---|
| 100% data,
All sites,
Small Recovery Window | Coordinated
DB backups at all sites involved in the replication configuration
(publisher, distributor and all subscribers). Somewhat complex to do. |
| 100% data,
All sites,
Medium Recovery Window | Backup
Publication DB and Distribution DB together. Replication can be
recovered from this point very easily without reconfiguring anything.
Just have to re-initialize the subscribers. This is the most common
approach being used. |
| 100% data,
All sites
Big Recovery Window | Backup
of Publication DB only. Can then reconfigure replication via scrips and
reinitialize distribution, and all subscribers fairly easily. |
When backing up environments, you need to back up the following at each site:
Publisher (published database, msdb, and master)
Distributor (distribution database, msdb, and master)
Subscribers (subscriber database, optionally msdb, and master when pull subscriptions are being done)
You should always make
copies of your replication scripts and keep them handy. At a minimum,
you need to keep copies at the publisher and distributor and one more
location, such as at one of your subscribers. You will use them for
recovery someday.
You shouldn’t forget to back up master and msdb when any new replication object is created, updated, or deleted.
If you have allowed
updating of subscribers using queued updates, you need to expand your
backup capability to include these queues.
In general, you will find
that even when you walk up and pull the plug on your distribution
server, publication server, or any subscribers, automatic recovery works
well to get you back online and replicating quickly, without human
intervention.
Some Thoughts on Performance
From a
performance point of view, the replication configuration defaults err on
the side of optimal throughput. That’s the good news. The bad news is
that everybody is different in some way, so you have to consider a bit
of tuning of your replication configuration. In general, you can get
your replication configuration working well by doing the following:
- Keeping the
amount of data to be replicated at any one point small by running agents
continuously, instead of at long, scheduled intervals.
- Setting
a minimum amount of memory allocated to SQL Server by using the Min
Server Memory option to guarantee ample memory across the board.
- Using
good disk drive physical separation rules, such as keeping the
transaction log on a separate disk drive from the data portion. Your
transaction log is much more heavily used when you opt for transactional
replication.
- Putting your snapshot working directory on
a separate disk drive to minimize disk drive arm contention. You should
use a separate snapshot folder for each publication.
- Publishing
only what you need. By selectively publishing only the minimum amount
of data required, you implement a much more efficient replication
configuration, which is faster overall.
- Trying to run snapshots in nonpeak times so your network and production environments aren’t bogged down.
- Minimizing transformation of data involved with replication.
Log Shipping
If you have a small need to
create a read-only (ad hoc query/reporting) database environment that
can tolerate a high degree of data latency, you might be a candidate for
using log shipping. Log shipping is still a feature for SQL Server
2008, but it will be deprecated by the next release. In other words, it
might be easy to use and easy to manage, but it is being phased out as a
feature of SQL Server. For those who have current log shipping configurations, it is
time to move to database mirroring. This transition will be easy because
the two capabilities are so much alike. (Actually, many aspects of
database mirroring came from log shipping.)
Data Replication and Database Mirroring for Fault Tolerance and High Availability
SQL Server 2008 allows you to
use combinations of options to achieve higher availability levels. A
prime example is combining data replication with database mirroring to
provide maximum availability of data, scalability to users, and fault
tolerance via failover at potentially each node in the replication
topology. You can start with the publisher and distributor, making them
both database mirror failover configurations. Building up a combination
of both options together is the best of both worlds: the super low
latency of database mirroring for fault tolerance and the high
availability (and scalability) of data through replication.